--しかし、PCは数10コアというような多数のコアは必要ない。したがって、同一チップにGPUを載せる余裕はある。
Dally:確かに、多数のCPUコアは必要ない。問題が並列に処理できるならGPUにやらせた方が効率が良い。1命令の処理に必要なエネルギーは、見かたにもよるがCPUは2~5nJだが、GPUは200pJで済んでいる。CPUは分岐予測やアウトオブオーダ実行のようにシリアル処理の問題を速く処理するために電力とチップ面積を使っている。
--GPUはどう発展していくのか。コアが増える以外の方向は?
Dally:当然、コア数の増加だけではない。アプリケーションの範囲を広げる機能を入れていく。1つは、よりイレギュラーな処理のサポートを拡充する。現状のGPUは、条件分岐の方向がスレッドごとに異なるようなコントロールダイバージェンスや、各スレッドがポインタで次のデータを読むデータダイバージェンスがあると性能がでない。このようなイレギュラーな処理でも性能を出すことを目指している。
また、現在のGPUでは、条件が少し変わると性能が大きく変わってしまうというケースがある。このような荒い凹凸を無くして滑らかに性能が変化するようにしたいと考えている。キャッシュはこのような効果を持つ機構の1つである。また、パフォーマンスが出ない理由を簡単にプログラマが理解できるような機構も役に立つ。
--どのようにしてイレギュラーな処理をサポートするのか?
Dally:キャッシュはその1つ。
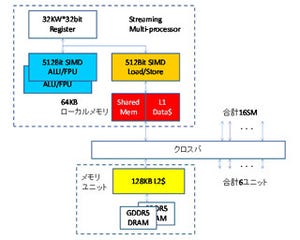
--今のFermiのキャッシュは小さすぎるのではないか?
Dally:Fermiのキャッシュは確かに小さいが、グラフィックスの処理には今のサイズで足りている。より広範なアプリに対応するためには、将来はキャッシュサイズの拡大が必要と考えている。
--DARPAのExtremeComputingではプログラミングの容易性が重要と言われているが?
Dally:DARPAに限らない。将来的にはすべてのプログラムが並列でヘテロジニアスな環境で動くようにならなければならないが、今のプログラムはシリアルで書かれている。並列プログラミングが容易にならないとだダメである。CUDAを拡張して、並列性とローカリティの記述を容易にしていくことを考えている。並列性や局所性のあるアルゴリズムはプログラマが考えなければならないが、その後は、コンパイラ、そしてAuto Tuningで個別のハードの違いは吸収していく方向である。
--世代ごとにマイクロアーキテクチャが変わり、GPUのリソースの量も世代によって変わってしまうのは問題ではないか?
Dally:ソフトの投資は守るようにようにアーキテクチャを変えて行く必要がある。
--CPUの世界では新しいCPUが出てもリコンパイルされないで古いバイナリを使い続けるケースが多いが、リコンパイルを期待できるのか?
Dally:CPUはx86命令をRISC風のuOPに変換し、さらにOut-of-Order実行でリオーダしている。これはある意味でリコンパイルをOn the Flyでハードウェアで行っている。しかもハードウェアがやるので十分な最適化はできていない。しかし、いろいろな中間解はありうる。GPUの仮想マシンであるPTX(NVIDIAのGPUの抽象化アセンブラ)は変わらないが、その下のハードウェア命令のSAS(NVIDIA GPUの機械命令)は変わるというような方向である。
--GPUのスレッド並列のプログラムをコンパイラが作れるのか?
Dally:スレッド並列アルゴリズムを考えたり、データの局所性があるアルゴリズムを考えるのはコンパイラよりも人間が優れている領域である。最近も、大規模なソートを効率よくGPUで実行するアルゴリズムが考案された。
--GPUはすでにエネルギー効率が高いが、今後、どうやって、さらに電力を減らすのか?
Dally:DARPAプログラムはプログラム容易性、エネルギー効率、レジリエンシー(耐故障性)が3つの主要な技術開発目標である。現在のGPUでもCPUよりエネルギー効率が良いが、DARPAの目標に対してはさらに10倍の改善が必要。レジスタのリード、キャッシュからの命令のリード、演算などの個別の消費エネルギーを測定して、エネルギー消費を減らすアーキテクチャを検討している。一例としては、レジスタを現状の大きなメインレジスタとオペランドレジスタに分離し、通常は小さなオペランドレジスタにアクセスするというような方法でレジスタアクセスのエネルギーを大幅に減らせる。
--それでも多数のFP演算器は必要だが、10倍のエネルギー効率は達成可能か?
Dally:演算器の消費エネルギーはそれほど大きくはなく、データを移動するためのエネルギーの方が大きい。FFTでは全データを他の全部の計算にばらまくというような必須のデータ移動があるが、多くの計算では必須ではないデータ移動があり、プログラムの作り方を含めて必須でないデータ移動を減らす。このようなアプローチを含めて色々な手段を適用すれば10倍の改善は可能と考えている。
--そのとき、GPUのアーキテクチャは現在のFermiとは変わるのか?
Dally:多くの点でアーキテクチャの詳細は変わることになると思うが、ハイレベルのアーキテクチャは同じで、多数のコアを持ち、高度のスレッド並列、GPU内部のメモリ階層はプログラマに見せるというようなビューは変わらないと考えている。