Unicode とテキストマッピング
.NET Framework や Java の文字列型は、標準で Unicode 文字の集合であることを定めていますが、C 言語では古くから文字列の内部表現が処理系に依存しています。C 言語には、単純文字を表す char 型と、ワイド文字を表す wchar_t 型の 2 つの文字型がありますが、どちらも符号化を定めているものではありません。仕様では、char 型は少なくとも ASCII コードに相当する基本文字集合の 1 文字を保存するサイズ(1 バイト)であり、wchar_t 型は char 型による単純文字では表現できない拡張文字セット 1 文字を保存するサイズである、という点のみ定められています。
ゼロからはじめるWindows API - WinMain 関数 すべての始まり編
C言語の学習および環境の構築は下記を参考にしてください
1.ゼロからはじめるC言語 - 環境構築編
2.ゼロからはじめるC言語 - 関数編
3.ゼロからはじめるC言語 - 型・定数編
4.ゼロからはじめるC言語 - 変数編
5.ゼロからはじめるC言語 - 選択編
6.ゼロからはじめるC言語 - 繰り返し編
7.ゼロからはじめるC言語 - 配列編
8.ゼロからはじめるC言語 - 構造体編
9.ゼロからはじめるC言語 - 自作関数編
10.ゼロからはじめるC言語 - ポインタ編
日本語のようなアジア諸言語の文字を 1 バイトで表現することはできないため、Windows では 1 文字を複数のバイトで表すマルチバイト文字 MBCS (Multibyte Character Set) と呼ばれる文字集合を使う方法と、1 文字を 16 ビットのワイド文字として表す Unicode を使う方法のいずれかを利用します。ただし、古い Windows 9x 系は Unicode に対応していません。
マルチバイト文字は可変長であり、文字によってバイト数が異なります。事実上、サポートされているのは 2 バイト文字までなので、マルチバイト文字の 1 文字は 1 バイトまたは 2 バイトとなります。一方、Unicode を使用した場合は、すべての文字が 16 ビットに固定されます。マルチバイト文字に比べ、メモリ効率は低下しますが処理速度は向上します。
新しくアプリケーションを開発する場合、原則として Unicode を使用してください。Windows 2000 以降、Windows は内部で Unicode を使用しているため、マルチバイト文字を使用すると内部で文字列の変換が発生するためオーバーヘッドが発生します。
マルチバイト文字は char 型、ワイド文字は wchar_t 型として扱われるため、Windows API では文字列を受け渡しする関数が文字セットごとに用意されています。マルチバイト文字対応の関数は名前の末尾が A、ワイド文字対応の関数は名前の末尾が W となっています。例えば、前回使用した MessageBox() 関数には、マルチバイト文字を受ける MessageBoxA() 関数と、ワイド文字を受ける MessageBoxW() 関数が用意されています。
MessageBoxA() 関数
int MessageBoxA(
HWND hWnd,
LPCSTR lpText,
LPCSTR lpCaption,
UINT uType
);
MessageBoxW() 関数
int MessageBoxW(
HWND hWnd,
LPCWSTR lpText,
LPCWSTR lpCaption,
UINT uType
);
違いは、パラメータとして受け取る文字列の型です。MessageBoxA() 関数の LPCSTR は const char * 型、MessageBoxW() 関数の LPCWSTR は const wchar_t * 型に相当します。MessageBox() 関数は、設定に応じてこれらのいずれかの関数にマッピングされます。このマッピングは、プロジェクトのプロパティから文字セットの設定を変更することで切り替えられます。
サンプル 01
#include <Windows.h>
int WINAPI WinMain(HINSTANCE hInstance, HINSTANCE hPrevInstance, LPSTR lpCmdLine, int nCmdShow)
{
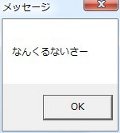
MessageBoxA(NULL, "なんくるないさー", "MBCS", MB_OK);
MessageBoxW(NULL, L"なんくるないさー", L"Unicode", MB_OK);
return 0;
}
図 01 サンプル 01 の実行結果 |
|
もちろんマルチバイト文字列用の関数に Unicode 文字列を渡したり、Unicode 用の関数にマルチバイト文字列を渡すと文字化けします。コンパイル時に、型の不一致による警告も発せられます。
この文字コードに関する問題は、プログラムの移植性を低下させる要因となります。古いシステム向けに書かれたマルチバイト文字列を使ったプログラムを Unicode 対応にしようとした場合、char * 型の変数を wchar_t 型に書き直し、文字列を受け渡しする関数も書き換えなければなりません。この問題を解決するために、マクロを駆使した汎用テキストによるマッピング機能が提供されています。
テキストマッピングでは、コンパイル時に UNICODE というシンボルが #define ディレクティブで定義されているかどうかを調べ、定義されていればワイド文字に変換されます。一方 _MBCSというシンボルが定義されている場合や、シンボルが未定義の場合はマルチバイト文字に変換されます。
| 汎用データ型 | ワイド文字(UNICODE) | マルチバイト文字(_MBCS) |
|---|---|---|
| TCHAR | wchar_t | char |
| LPTSTR | wchar_t * | char * |
| LPCTSTR | const wchar_t * | const char * |
これらの汎用データ型は、プリプロセッサディレクティブを用いて UNICODE というシンボルが定義されているかによって型が展開されます。たとえば、TCHAR 型は次のように実装されています。
typedef wchar_t WCHAR;
#ifdef UNICODE
typedef WCHAR TCHAR;
#else
typedef char TCHAR;
#endif
変数や文字列を受け取る関数の仮パラメータの型に汎用データ型を用いることで、コンパイル時のシンボルの設定を変更するだけで文字セットを切り替えることができます。これらの汎用データ型を扱うとき、文字列リテラルも TEXT() マクロを使うことで切り替えられます。
TEXT() マクロ
#ifdef UNICODE
#define TEXT(quote) L##quote
#else
#define TEXT(quote) quote
#endif
TEXT マクロは UNICODE シンボルが定義されている場合、パラメータで受けた単純文字列リテラルに L 接頭辞を付加してワイド文字列リテラルに展開します。そうでなければ、パラメータの文字列をそのまま変換しません。
サンプル 02
#include <Windows.h>
int WINAPI WinMain(HINSTANCE hInstance, HINSTANCE hPrevInstance, LPSTR lpCmdLine, int nCmdShow)
{
#ifdef UNICODE
MessageBox(NULL, TEXT("なんくるないさー"), TEXT("Unicode"), MB_OK);
#else
MessageBox(NULL, TEXT("なんくるないさー"), TEXT("MBCS"), MB_OK);
#endif
return 0;
}
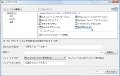
文字セットを変えるには、VisualC++ 2008のプロジェクトのプロパティを開いて、「構成プロパティ」→「全般」の「文字セット」で設定を「変更してください。
サンプル 02 は、TEXT() マクロを使って MessageBox() 関数に渡す文字列を展開しています。この場合、UNICODE シンボルが定義されていればワイド文字になり、そうでなければマルチバイト文字になります。このプログラムでは、結果の違いを視覚的に確認するためにタイトルに表示する文字列を分けていますが、この方法であれば Unicode とマルチバイト文字のプログラムを書き分けることなく、シンボルの定義を変更するだけで切り替えられます。
これに加えて、Windows API では汎用データ型に対応した文字列操作関数を提供しています。関数名は C 標準関数で提供される文字列操作関数 str~() の頭に小文字の l を付け加えます。文字数を取得する strlen() 関数に対応する lstrlen() 関数、文字列を複製する strcpy() 関数に対応する lstrcpy() 関数という形です。