今更述べるまでもなく、Web文化は米国が発祥の地。そのため当初は、日本語など2バイト文字を考慮されず、筆者がはじめてWebブラウジングを体験したWindows 3.1全盛期のWebブラウザは熟成度も相まって、英数字や漢字が混ざった文字組みはひどいものでした。その反動なのか2005年頃から、日本語文字列の混在する英単語の前後に半角スペースを入れ、表示を見やすくするというテクニックが持てはやされました。
確かにWebブラウザ上では、見やすくなるテクニックながらも、Wordなどで再加工するため、テキストデータとして用いるときは、肝心の半角スペースがじゃまな存在となってしまいます。そもそも半角スペースを用いるテクニックは、印刷物などで用いられる文字組みを擬似的に再現したもの。
文書の組版を規定したJIS規格であるJIS X 4051「日本語文書の組版方法」では、文字と文字の間の空き量が厳密に定められています。たとえば句点の字幅と後アキは二分、和文と欧文の前後で四分アキと決まっているため、一般的に出版されている印刷物は文字が見やすくなっているのです(もちろんすべての印刷物が、JIS規格に沿って作られているわけではありません)。
つまり、この英単語の前後四分アキをWeb上で再現しているのが前述の半角スペースなのです。このことを踏まえますと、Webブラウザ側が対応すれば問題解決となるはずなのですが、特定の言語にあわせたチューニングが行なわれる気配はなく、一般的にはCSSなど加工制御言語で処理するのが現実的。
某メーカーのWebサイトを例に挙げてみますと、サポートページでは英単語の前後に半角スペースを設けていますが、製品紹介ページでは半角スペースを用いておらず、そのまま全角文字から半角英単語が連なっている文書を見かけました。どちらが正しいか否かはさておいて、半角スペースで4分アキを再現しますと、Web上では見やすくてもテキストとしては扱いにくく、半角スペースを用いないとWeb上で見にくくなるのは事実です。そこで、和文中にある欧文の前後にある半角スペースを制御する正規表現を考えてみましょう。
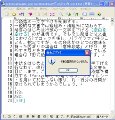
今回のポイントは和文中に含まれる半角英単語を、どのようにピックアップするかという点(全角英単語を半角に戻す正規表現はこちらをご覧ください(。英字だけですから「[a-Z]」と英字のはじまりと終わりをブラケットで囲めば済みますが、秀丸のエスケープシーケンスを用いることでより簡単に表現できます。「\w」は半角アルファベットと「_(半角アンダースコア)」だけで構成される文字列にマッチするエスケープシーケンス。これ検索で用いれば「\w」だけで英単語のみ強調表示されます(図01)。
 |
図01 検索ダイアログを開き、「検索」に「\w」と入力して[上検索][下検索]いずれかのボタンをクリックすれば、和文中に含まれる英単語が強調表示されます |
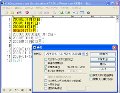
今度は置換に取りかかりましょう。英単語のピックアップは「\w」で済むため、タグ付き正規表現である「\f」で区切れば、検索用正規表現は「\f\w」、置換用正規表現は「 \1 」となります。たしかにこれでも間違いではありませんが、実行結果を見ると句読点の後に続く英単語の前にも半角スペースが入るため、かんばしくありません(図02~03)。
 |
図02 置換ダイアログを開き、「検索」に「\f\w」と入力。「置換」に「 \1 」と入力して[全置換]ボタンをクリックします |
 |
図03 すると英単語の前後に半角スペースが挿入されました。画面の例ではわかりやすくするため、半角スペースを強調表示しています |
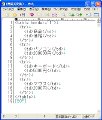
しかし、秀丸のダイアログに頼った置換では、複数の条件を与えても、置換によるアクションはひとつのみ。そのため先の問題を回避するには2段階の置換操作が必要となります。欧文の後に句読点が来ないことを前提にしますと、検索文字列として半角および全角、句読点などが後方にない欧文だけをピックアップし、置換文字列を「\1 」と、英単語の後部に半角スペースを加える正規表現を与えます。これで欧文の後ろに半角スペースが加わりました(図04~05)。
 |
図04 置換ダイアログを開き、「検索」に「\w\f[^ 、。]」と入力。「置換」に「\0 \1」と入力して[全置換]ボタンをクリックします |
 |
図05 これで英単語の後部に半角スペースが挿入されました。画面の例ではわかりやすくするため、半角スペースを強調表示しています |
正規表現:欧文の後方に半角スペースを加える
検索文字列:\w\f[^ 、。]
置換文字列:\0 \1
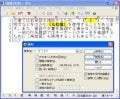
次に検索文字列を全角スペースおよび句点などを前方に持たない英単語として「[^ 、。]\f\w」と指定します。この際、置換文字列もマッチしてしまうので、和文を残すために「\0 \1」と指定しましょう。これで正しく置換できました。ちなみにこの正規表現ではURLを含む文字列を誤認識します。今回の記事ではそこまで対応しませんが、マッチさせたくない条件が発生した場合はブラケットに正規表現を加えていきましょう(図06~07)
 |
図06 続いて置換ダイアログを開き、「検索」に「[^ 、。]\f\w」と入力。「置換」に「\0 \1」と入力して[全置換]ボタンをクリックします |
 |
図07 これで英単語の前部に全角スペースや区点などを持たない欧文のみ半角スペースが挿入されました。画面の例ではわかりやすくするため、半角スペースを強調表示しています |
正規表現:句読点などを前方に持たない欧文の前方に半角スペースを加える
検索文字列:[^ 、。]\f\w
置換文字列:\0 \1
逆に半角スペースを削る場合は、検索文字列を「\w\f 」、置換文字列を「\0」で置換操作を実行し、次に検索文字列を「 \f\w」、置換文字列を「\1」してください。半角スペースの挿入と同じように英単語の前後にある半角スペースだけを削除できます(図08~11)。
正規表現:欧文の後方にある半角スペースを削除する
検索文字列:\w\f ※後に半角スペース
置換文字列:\0
正規表現:欧文の前方にある半角スペースを削除する
検索文字列: \f\w ※前に半角スペース
置換文字列:\1
 |
図08 置換ダイアログを開き、「検索」に「\w\f 」と入力。「置換」に「\0」と入力して[全置換]ボタンをクリックします |
 |
図09 これで英単語の後部にある半角スペースが削除されました。画面の例ではわかりやすくするため、半角スペースを強調表示しています |
 |
図10 続いて置換ダイアログを開き、「検索」に「 \f\w」と入力。「置換」に「\1」と入力して[全置換]ボタンをクリックします |
 |
図11 これで英単語の前部にある半角スペースが削除されました。半角スペースの強調表示設定を行なっていますが、すべて削除されているため、何も強調表示されていません |
阿久津良和(Cactus)